Recently I was reviewing the security posture of an agentic RAG application we’d built across several of the previous posts in this series, and I had a bit of a moment. The application touched identity, networking, content safety, data access controls, evaluation pipelines, and governance policies. Each layer had its own Azure service, its own configuration, and its own documentation trail. It struck me that what we really needed was a single reference architecture that pulled it all together.
So I sat down and built one. What follows is a six-layer security model that organises every Azure AI security capability into a practical checklist you can take into your next project. Whether you’re building your first agent or hardening an existing one, this is the framework I wish I’d had six months ago.
The Six-Layer Security Model
Here’s the model at a glance. Each layer addresses a distinct category of risk, and together they form a defence-in-depth architecture:
| Layer | What It Protects | Key Azure Services |
|---|---|---|
| 1. Identity | Who (or what) is authorised to act | Entra Agent ID, Conditional Access, RBAC |
| 2. Network | How traffic flows between components | Private Endpoints, VNets, Global Secure Access |
| 3. Content | What the model can say and do | Content Safety, Prompt Shields, Task Adherence, PII Filters |
| 4. Data | What information the model can access | Document-Level Access Control, Purview Labels, ACLs |
| 5. Evaluation | Whether the model behaves correctly | Foundry Evaluators, Red Teaming Agent, Defender for Foundry |
| 6. Governance | Compliance, audit, and lifecycle | Agent 365, Azure Policy, Audit Logs, Retention Policies |
Let’s walk through each one.
Layer 1: Identity
This is where it all starts. If you’ve read Post 11 on Entra Agent ID, you know that Microsoft now treats AI agents as first-class identities, just like human users and service principals.
The key capabilities:
- Entra Agent ID: Every agent gets a unique identity in your directory. No more shared service accounts for AI workloads.
- Conditional Access for agents: Apply the same Zero Trust policies to agents that you apply to humans. Require compliant devices, restrict by location, enforce MFA for sensitive operations.
- Agent Registry: An enterprise-wide inventory of all agents, whether they’re built in Foundry, Copilot Studio, or third-party platforms.
- Agent Risk Management: Risk scoring for agent identities, surfaced in Entra ID Protection alongside your human identity risk signals.
- Specialised RBAC roles: Agent Owners, Sponsors, and Managers, giving you granular control over who can create, operate, and retire agents.
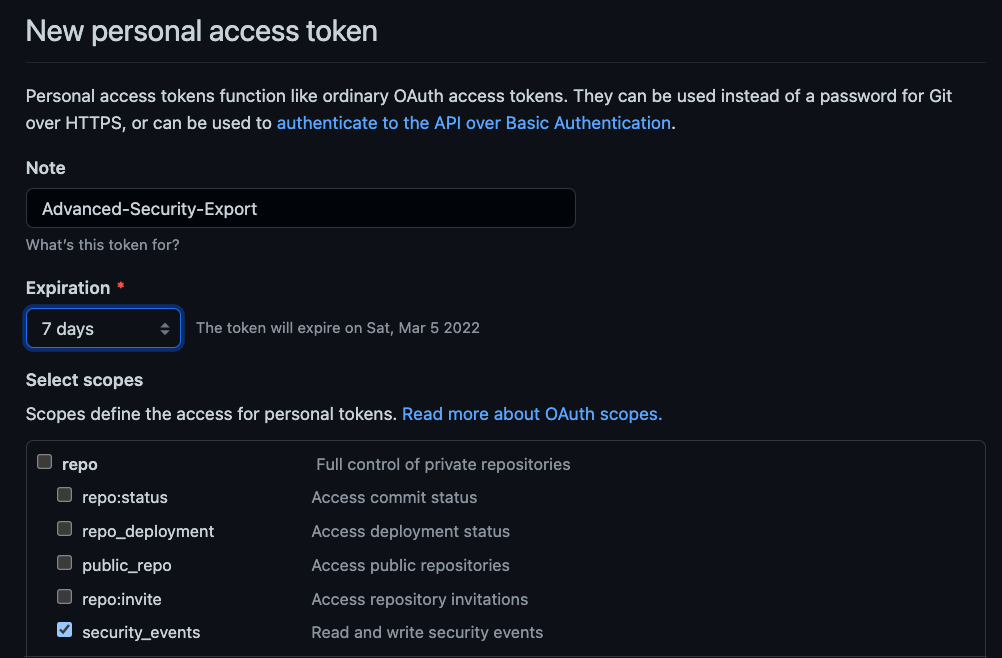
Practitioner tip: If you’re deploying agents in production, move away from API key authentication immediately. Use managed identities with Entra ID. API keys don’t give you the audit trail, conditional access, or risk scoring that Entra provides.
Layer 2: Network
Network isolation for AI services follows the same patterns you’d use for any Azure PaaS workload, but with a few AI-specific additions:
- Private endpoints for Foundry resources, AI Search, and Content Understanding. Keep your model inference traffic off the public internet.
- VNet integration across all AI services. Your agents, models, and data stores should communicate over private networks.
- AI Prompt Shield via Global Secure Access: This is the interesting one. It’s a network-layer defence that inspects traffic for prompt injection attacks before they even reach your model. Think of it as a WAF for AI.
Note: Some Foundry features (Hosted Agents, Traces, Workflow Agents) don’t yet fully support private networking. Check the feature limitations table before assuming full network isolation.
Layer 3: Content
This is the layer most people think of when they hear “AI safety,” and we covered it thoroughly in Post 10 on Content Safety. The key features:
- Task Adherence: Detects when an agent goes off-script. If your flight-booking agent tries to invoke a money-transfer tool, Task Adherence catches it before the tool executes.
- Prompt Shields with Spotlighting: Defends against indirect prompt injection in RAG pipelines. Tags input documents with special formatting to signal lower trust levels to the model.
- PII Detection Content Filter: Built-in detection and blocking of personally identifiable information in model outputs. Critical for GDPR, CCPA, and Privacy Act compliance.
- Custom Categories: Define your own harmful content patterns for domain-specific safety (brand safety, industry-specific restrictions).
- Multimodal Content Safety: Text and image analysis together for more accurate detection.
What each layer catches:
| Feature | Catches |
|---|---|
| Traditional content filters | Hate speech, violence, self-harm, sexual content |
| Prompt Shields | Direct and indirect prompt injection attacks |
| Task Adherence | Agent scope creep, misaligned tool invocations |
| PII Filters | Email addresses, phone numbers, government IDs in outputs |
| Custom Categories | Domain-specific harmful content |
Layer 4: Data
The data layer controls what information your AI application can access, and critically, what it can access on behalf of a specific user. We covered this in Post 9 on Agentic RAG:
- Document-Level Access Control in AI Search: Flows ADLS Gen2 ACLs to searchable documents. Query results are automatically filtered by user identity, so two users asking the same question see different results based on their permissions.
- SharePoint ACL integration: Same principle, applied to SharePoint-indexed content.
- Purview sensitivity label indexing: Search indexes respect your Purview sensitivity labels. Confidential documents stay confidential even when they’re in a search index.
- Confidential Computing for AI Search: Data-in-use encryption for search workloads that handle highly sensitive data.
The pattern here is identity propagation. Your user’s Entra ID identity flows from the client, through the agent, into the retrieval layer, and back. At no point should the agent have broader data access than the user it’s serving.
Layer 5: Evaluation
This is the layer that catches problems before they reach production, and continues catching them after deployment. We covered this in Post 4 on Evaluating and Red-Teaming:
- Foundry agentic evaluators: Purpose-built evaluators for agent behaviour:
IntentResolutionEvaluator: Did the agent understand the request?ToolCallAccuracyEvaluator: Did it invoke the right tools correctly?TaskAdherenceEvaluator: Did it stay within scope?GroundednessProEvaluator: Are responses grounded in provided context?CodeVulnerabilityEvaluator: Does generated code contain security vulnerabilities?
- AI Red Teaming Agent: Automated adversarial testing powered by Microsoft’s PyRIT framework. Simulates jailbreak, indirect injection, and multi-turn attacks on a schedule.
- Defender for Foundry: Runtime security posture management with alerts, recommendations, and an AI Security Posture dashboard.
In my opinion, this is the layer where most organisations under-invest. You wouldn’t ship a web application without automated tests. Don’t ship an agent without automated evaluations.
Layer 6: Governance
The governance layer ensures your AI deployments meet regulatory requirements and organisational policies:
- Microsoft Agent 365: The unified governance control plane for agents. DLP enforcement, insider risk management, audit trails, compliance policies, and retention/deletion policies for agent-generated content.
- Azure Policy integration: Apply policies to Foundry resources just like any other Azure resource. Enforce tagging, restrict regions, require private endpoints.
- Foundry built-in governance: RBAC, audit logs, and compliance controls baked into the platform.
- AI regulation compliance: Regulatory templates for emerging AI regulations (EU AI Act, Australian AI Ethics Principles).
The Practitioner’s Checklist
Here’s the checklist I use when reviewing an AI application’s security posture. Copy this into your project wiki and tick them off:
Identity:
- Agents use Entra managed identities (no API keys in production)
- Conditional Access policies target agent identities
- Agents are registered in the Agent Registry
- RBAC roles are assigned with least privilege
Network:
- Private endpoints configured for Foundry, AI Search, Content Understanding
- VNet integration enabled across all AI services
- AI Prompt Shield enabled via Global Secure Access (if available)
Content:
- Content filters enabled with appropriate severity thresholds
- Task Adherence configured for all agentic workloads
- Prompt Shields Spotlighting enabled for RAG pipelines
- PII detection filter enabled for outputs
Data:
- Document-Level Access Control configured in AI Search
- User identity propagated through the full retrieval chain
- Sensitivity labels indexed and respected
- No over-privileged service accounts accessing data stores
Evaluation:
- Agentic evaluators running in CI/CD pipeline
- Red Teaming Agent scheduled for continuous adversarial testing
- Defender for Foundry enabled with alert notifications
Governance:
- Agent 365 configured with DLP and retention policies
- Azure Policy enforcing organisational standards
- Audit logs flowing to centralised SIEM
- Regulatory compliance templates applied
What Happens Without Each Layer
To drive the point home, here’s what you’re exposed to without each layer:
| Missing Layer | Risk |
|---|---|
| Identity | Agents operate with shared credentials; no audit trail; no access control |
| Network | Model inference traffic exposed to internet; data exfiltration via public endpoints |
| Content | Prompt injection attacks succeed; harmful outputs reach users; agent scope creep |
| Data | Users see documents they shouldn’t; sensitive data leaked through RAG responses |
| Evaluation | Broken agent behaviour discovered by users, not testing |
| Governance | No compliance evidence; no retention controls; regulatory violations |
Wrapping Up
The agentic era is here, and it’s moving fast. But the security principles haven’t changed: defence in depth, least privilege, identity-driven access, and continuous evaluation. What’s changed is the tooling. Microsoft has shipped a remarkably comprehensive security stack for AI in 2025, and if you implement even half of the checklist above, you’ll be ahead of most organisations.
The six-layer model isn’t meant to be prescriptive. Not every application needs every layer at full maturity on day one. Start with identity and content safety (layers 1 and 3), because those give you the most risk reduction for the least effort. Then work outward. The checklist is there for when you’re ready to go deeper.
As always, feel free to reach out with any questions or comments!
Until next time, stay cloudy!