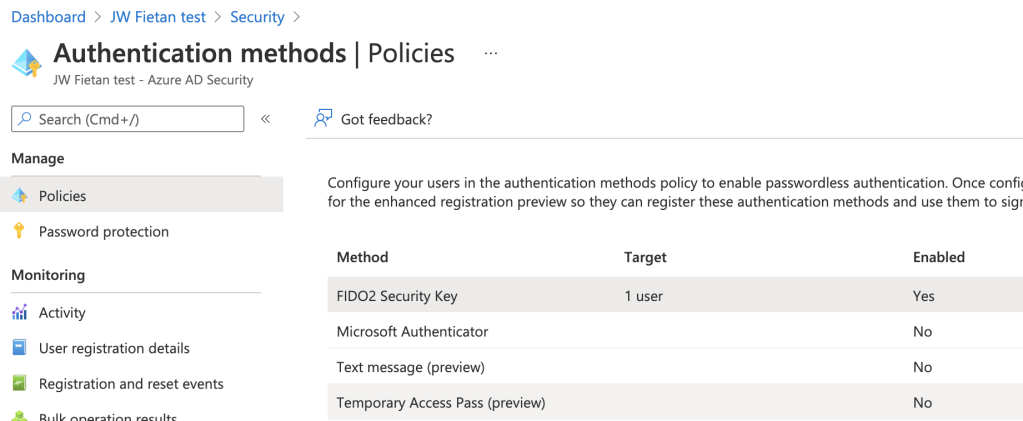
Every second customer conversation I’ve had this year has included the same question: “We’ve been using Azure OpenAI for chat completions. How hard is it to build an actual agent?” Six months ago, my honest answer would have been “doable, but bring duct tape.” Not anymore. What used to require stitching together the Assistants API, custom orchestration logic, and a prayer to the demo gods is now a managed, production-supported platform with proper tooling and observability.
The Foundry Agent Service graduated to General Availability at Build 2025, and it’s the real deal. In this post, I’ll walk through building an agent from scratch using the .NET SDK, adding tools, testing it, enabling tracing with Application Insights, and getting it production-ready. If you’ve been curious about agents but haven’t built one yet, this is your starting point.
What Even Is an Agent?
Before we dive in, let’s clear up what “agent” actually means in this context, because the term gets thrown around a lot.
An agent is an AI application that uses a large language model to reason about user requests and take autonomous actions to fulfil them. Unlike a basic chatbot that just generates text, an agent can call tools, access external data, and make decisions across multiple steps to complete a task. Every agent has three core components:
- Model (LLM): Provides the reasoning and language capabilities
- Instructions: Define the agent’s goals, constraints, and behaviour
- Tools: Give the agent access to data or actions (search, code execution, API calls)
The Foundry Agent Service handles the hosting, scaling, identity, observability, and enterprise security. You focus on the agent logic.
Prerequisites
Before we start, you’ll need:
- An Azure subscription with a Microsoft Foundry resource and project
- A model deployed in your project (I’m using
gpt-4.1for this walkthrough) - .NET 8.0+ with the
Azure.AI.Projects,Azure.AI.Extensions.OpenAI, andAzure.Identitypackages installed - An Application Insights resource (for tracing, which we’ll set up later)
dotnet add package Azure.AI.Projects
dotnet add package Azure.AI.Extensions.OpenAI
dotnet add package Azure.IdentityStep 1: Create Your First Agent
First cab off the rank, let’s create a basic agent. The new SDK uses a PromptAgentDefinition to define your agent’s model, instructions, and tools:
// Install packages:
// dotnet add package Azure.AI.Projects
// dotnet add package Azure.AI.Extensions.OpenAI
// dotnet add package Azure.Identity
using Azure.Identity;
using Azure.AI.Projects;
using Azure.AI.Extensions.OpenAI;
string projectEndpoint = "https://your-resource.ai.azure.com/api/projects/your-project";
// Create the project client
AIProjectClient projectClient = new(
endpoint: new Uri(projectEndpoint),
tokenProvider: new DefaultAzureCredential());
// Create a simple agent
AgentDefinition agentDefinition = new PromptAgentDefinition("gpt-4.1")
{
Instructions = "You are a helpful IT helpdesk agent. " +
"Answer technical questions clearly and concisely. " +
"If you don't know the answer, say so honestly.",
};
AgentVersion agent = await projectClient.Agents.CreateAgentVersionAsync(
"helpdesk-agent",
options: new(agentDefinition));
Console.WriteLine($"Agent created: {agent.Name} (version: {agent.Version})");That’s it for a basic agent. No infrastructure to provision, no containers to deploy, no orchestration framework to configure. The Agent Service handles all of that.
Step 2: Add Some Tools
A basic agent is nice, but an agent with tools is where it gets interesting. Let’s give our helpdesk agent web search capability and a code interpreter:
var agentDefinition = new PromptAgentDefinition("gpt-4.1")
{
Instructions = "You are a helpful IT helpdesk agent. " +
"Use web search to find current documentation and solutions. " +
"Use the code interpreter to run diagnostic scripts when needed. " +
"Always cite your sources.",
Tools = {
new WebSearchToolDefinition(),
new CodeInterpreterToolDefinition(),
}
};
AgentVersion agent = await projectClient.Agents.CreateAgentVersionAsync(
"helpdesk-agent-v2",
options: new(agentDefinition));The tool catalog in Foundry has over 1,400 tools available, including:
- Web Search for real-time information via Bing
- Code Interpreter for running Python in a sandboxed container
- Azure AI Search for querying your enterprise search indexes
- File Search for document retrieval
- MCP servers for connecting to the Model Context Protocol ecosystem
- Azure Functions for custom serverless tools
- Microsoft Fabric for enterprise data queries
You can also define custom function tools for anything specific to your domain.
Step 3: Talk to Your Agent
Now let’s have a conversation with our agent. The Agent Service uses the Responses API under the hood, so you interact with agents through the ProjectResponsesClient:
// Get a responses client scoped to the agent
ProjectResponsesClient responsesClient = projectClient.ProjectOpenAIClient
.GetProjectResponsesClientForAgent(agent.Name);
// Send a message to the agent
ResponseResult response = await responsesClient.CreateResponseAsync(
new CreateResponseOptions
{
InputItems = { ResponseItem.CreateUserMessageItem("How do I reset a user's MFA in Microsoft Entra ID?") }
});
Console.WriteLine(response.GetOutputText());The GetProjectResponsesClientForAgent method returns a client that automatically routes requests through your agent, including its instructions and tools. The agent will use web search if it needs current information and code interpreter if the task requires computation.
For streaming responses (which is what you’d want in a real UI):
await foreach (StreamingResponseUpdate update in responsesClient.CreateResponseStreamingAsync(
new CreateResponseOptions
{
InputItems = { ResponseItem.CreateUserMessageItem(
"What's the PowerShell command to check Azure AD sync status?") }
}))
{
if (update is ResponseTextDeltaUpdate textDelta)
{
Console.Write(textDelta.Delta);
}
else if (update is ResponseItemDoneUpdate itemDone)
{
if (itemDone.Item is MessageResponseItem message)
{
foreach (var annotation in message.Content.Last().Annotations)
{
if (annotation is UrlCitationAnnotation citation)
{
Console.WriteLine($"\nSource: {citation.Url}");
}
}
}
}
}Step 4: Enable Tracing with Application Insights
Here’s something I wish I’d had in every agent demo I’ve put together: built-in tracing. The Agent Service automatically captures traces for every model call, tool invocation, and decision your agent makes. You just need to connect Application Insights.
In your Foundry project settings, link an Application Insights resource. Once connected, every agent interaction is traced using OpenTelemetry semantic conventions and surfaces in the Foundry portal’s Observability section.
What you can see in the traces:
- The full conversation thread with user inputs and agent outputs
- Every tool call the agent made, including inputs and outputs
- Model reasoning steps and token usage
- Latency breakdown across each step
- Error details when things go wrong
This is genuinely invaluable for debugging. When someone says “the agent gave me a wrong answer,” you can trace back through the exact sequence of tool calls and model reasoning to understand why. No more black-box debugging.
Step 5: Model Selection Guidance
Choosing the right model for your agent matters more than you might think. Here’s my rough guide based on what I’ve seen work well:
| Model | Best For | Trade-off |
|---|---|---|
| gpt-4.1 | General-purpose agents, complex reasoning | Higher cost, excellent quality |
| gpt-4.1-mini | Production agents with good quality/cost balance | Slightly less capable, much cheaper |
| gpt-4.1-nano | High-volume, simple task agents | Fast and cheap, less nuanced |
| o4-mini | Agents needing multi-step reasoning | Slower (thinking time), very capable |
| gpt-5-mini | Latest generation, strong reasoning | Best quality/cost ratio for new projects |
The beauty of the Agent Service is that you can swap models without changing your agent code. Start with gpt-4.1-mini for development, upgrade to gpt-5-mini for production if you need better quality.
Step 6: Publish and Monitor
Once you’re happy with your agent, you can publish it to create a stable, versioned endpoint:
// Publish the agent (creates a stable endpoint)
var published = await projectClient.Agents.PublishAsync(
agentName: agent.Name,
agentVersion: agent.Version);Published agents get:
- Versioning: Every iteration is snapshotted. Roll back to any previous version.
- Stable endpoints: A production URL that doesn’t change between versions.
- Distribution: Share through Microsoft Teams, Microsoft 365 Copilot, or the Entra Agent Registry.
For monitoring, the Foundry portal provides service metrics dashboards showing agent run counts, response latency, tool invocation patterns, and error rates. You can set up alerts on these metrics through Azure Monitor, same as any other Azure resource.
Gotchas and Tips
A few things I’ve learned from building agents on this platform:
- Be specific in your instructions. Vague instructions like “be helpful” lead to inconsistent behaviour. Tell the agent exactly what it should and shouldn’t do, what tools to prefer, and how to handle edge cases.
- Test with diverse inputs. Agents can surprise you. Run a proper evaluation before going to production.
- Watch your tool usage costs. Web search and code interpreter have their own pricing on top of model token costs. Monitor your tool invocation patterns.
- Use
tool_choicestrategically. Settingtool_choice="required"forces the agent to use a tool, which is useful when you know a tool call is needed (like grounding on search data).
Wrapping Up
Building an agent on Microsoft Foundry has gone from a multi-day infrastructure exercise to something you can genuinely get running in an afternoon. The managed runtime, built-in tools, tracing with Application Insights, and production publishing workflow mean you can focus on your agent’s logic rather than plumbing.
As always, feel free to reach out with any questions or comments!
Until next time, stay cloudy!